L'IA est-elle injuste ?
Le 11 février 2013 aux États-Unis, Eric Loomis est arrêté par la police alors qu'il conduisait une voiture ayant été aperçue dans une fusillade. Il a ensuite été inculpé et a plaidé coupable pour avoir tenté d'échapper à un officier. Lors de la détermination de sa peine, le juge a pris en compte son casier judiciaire ainsi qu'un score attribué par un outil informatique appelé COMPAS. Le principe de ce logiciel c'est d'évaluer le risque de récidive d'un accusé à partir de ses données personnelles, ainsi que ses réponses à un questionnaire. Le programme repose sur un algorithme propriétaire, c'est-à-dire dont le fonctionnement est conçu et gardé secret par une entreprise privée, et influence les décisions de justice de mise en liberté ou de condamnation dans plusieurs états américains, comme New York, la Californie ou la Floride.

COMPAS a donc évalué Eric Loomis comme présentant un risque élevé de récidive, et il a été condamné à six ans de prison. Loomis a contesté cette décision, arguant que le fait que le juge ait pris en compte le résultat d'un algorithme au fonctionnement secret et impossible à examiner constituait une violation du droit à un procès équitable. Donc naturellement, il a fait appel.
3 ans plus tard, en 2016, l'appel a été rejeté, et la légalité de l'outil COMPAS a été établi par la cour suprême des États-Unis. À partir de ce jour, il fut donc reconnu et accepté que la décision d'un juge puisse être influencée par un programme informatique, au fonctionnement opaque. Un événement historique pour l'intelligence artificielle, bien qu'il nous laisse un goût amer.
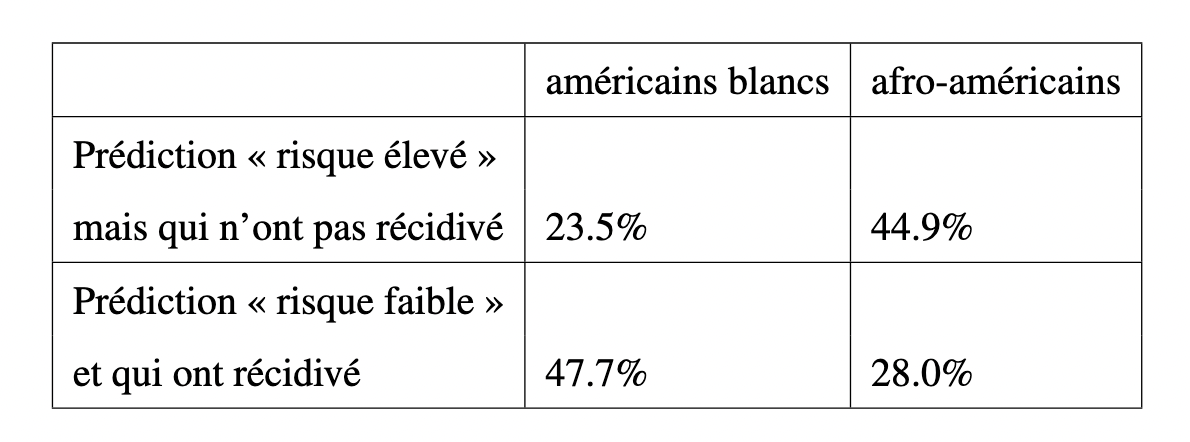
La même année, ProPublica mène une enquête sur environ 7000 dossiers de justice ayant eu recours à cet outil algorithmique, et révèle un fait troublant. COMPAS, présenté comme objectif et impartial, surestimait le risque de récidive pour les personnes noires, les classant à tort en "risque élevé" deux fois plus souvent que pour les personnes blanches. Il obtenait un taux de faux positifs - c'est-à-dire ici prédire « à haut risque » alors que finalement la personne ne récidive pas - de presque 45% pour les noirs, contre 23,5% pour les blancs. Plus généralement, l'algorithme d'aide à la décision judiciaire utilise tout un tas d'informations sur l'accusé, chacune plus discriminatoire : Résultats scolaires, emploi, environnement social, lieu d'habitation, ou encore liens familiaux.
Et si tout cela vous semble scandaleux, sachez que le logiciel est toujours utilisé, à ce jour, en 2025, car il est considéré utile pour certains juges. Et ce, malgré le fait que son fonctionnement soit tenu secret par une entreprise, et malgré ses limitations et ses biais racistes ayant été mis en lumière il y a presque 10 ans.
Et COMPAS n'est pas un cas isolé. Cet exemple illustre un problème bien plus vaste, et inhérent à l'intelligence artificielle : les biais algorithmiques. Et c'est justement de ça dont on va parler aujourd'hui, les biais dans l'intelligence artificielle. Nous allons donc essayer d'en comprendre les origines, les conséquences, et de voir s'il y a des solutions possibles pour les éviter.
Biais : KÉSACO ?
Alors, reprenons depuis le début. Déjà, qu'est-ce qu'un biais ? Le mot "biais" est un terme assez courant, qu'on retrouve dans tout un ensemble de contextes. Par exemple les biais cognitifs comme le biais de confirmation, ou le biais de halo. Les biais cognitifs sont des erreurs dans nos raisonnements et dans notre compréhension du monde. Ce sont des défauts intrinsèques à notre pensée. On parle également de biais en linguistique, avec le biais de traduction, ou le biais culturel, qui agissent comme des prismes déformant le sens d'un message. Il y a aussi les biais statistiques, comme le biais de sélection ou le biais du survivant, qui faussent et polluent les résultats des études et des sondages. Et il y a aussi le cas, donc, qui nous intéresse ici, qu'on nomme généralement le "biais algorithmique". Dans tous ces exemples, l'idée est toujours à peu près similaire : le biais est une erreur systématique. Pas une simple erreur aléatoire. Une erreur qui va toujours dans la même direction.
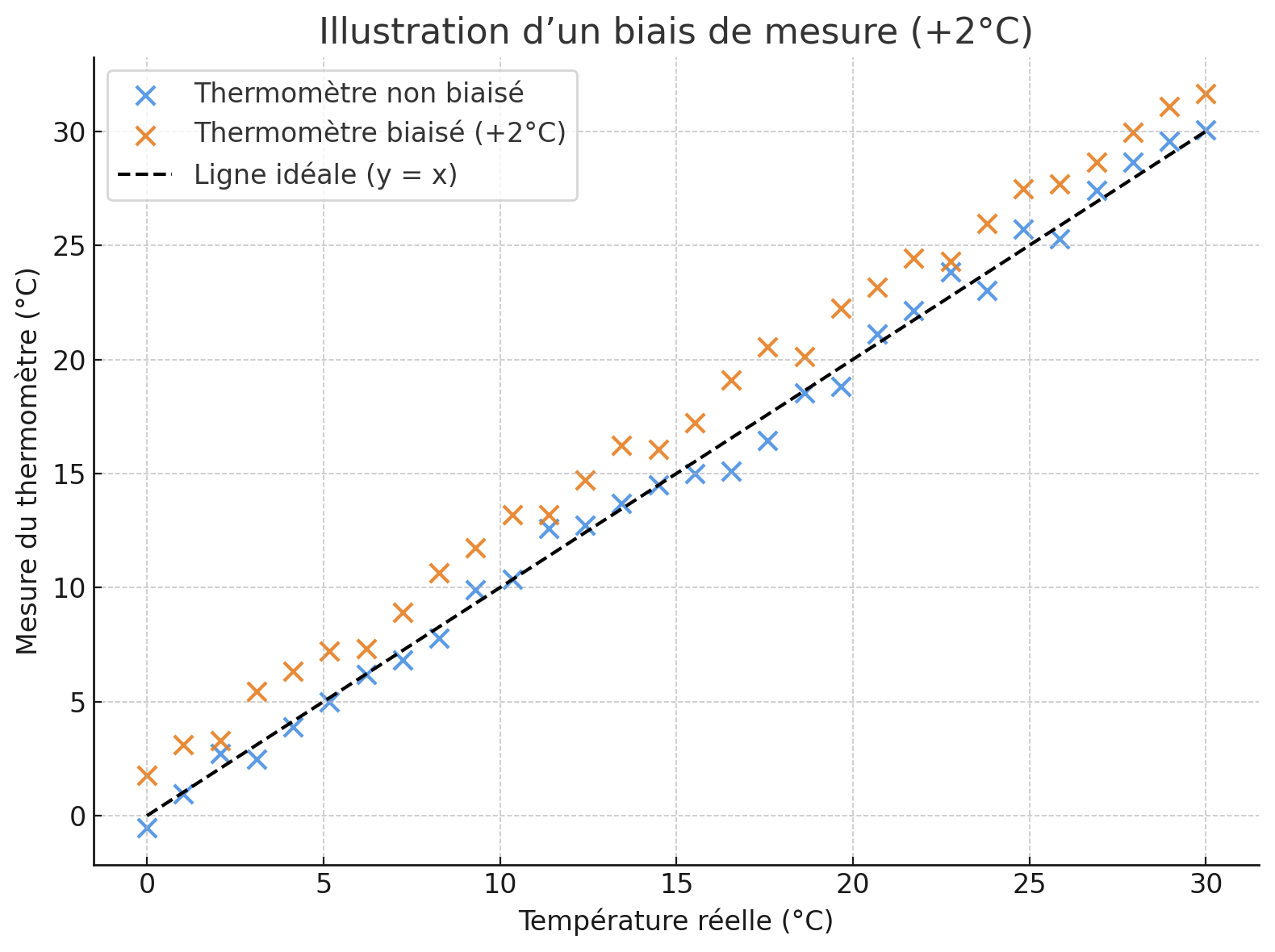
Illustrons cette idée avec un exemple simple. Vous avez un thermomètre, qui, comme son nom l'indique, mesure la température. Sauf que votre thermomètre a la fâcheuse tendance à toujours rajouter 2 degrés. Quand il fait 5 degrés dehors, il indique 7, et quand il fait 20 degrés, il indique 22 ! Il est plutôt précis, mais mal calibré, et son erreur va toujours dans la même direction : cette erreur, c'est un biais. Il ne se trompe pas au hasard, il se trompe toujours dans le même sens. Un autre biais que votre thermomètre pourrait avoir, c'est de surestimer l'hiver. Alors, il deviendrait particulièrement imprécis pendant les mois de janvier et février.
En apprentissage automatique, c'est pareil : Un algorithme peut se tromper, certes. Mais s'il se trompe toujours en faveur ou en défaveur d'un même groupe alors ce n'est plus une simple erreur. C'est un biais. Et, comme on l'a vu, cela peut s'avérer particulièrement problématique, en reproduisant notamment des formes de racisme, de sexisme et de discrimination sociale.
On a évoqué le cas de la justice, mais ce n'est qu'un champ d'application parmi des centaines d'autres. On observe ce problème :
- Dans le recrutement, avec des algorithmes de tri de CV qui pénalisent les femmes, les noms à consonance étrangères, ou encore les parcours atypiques,
- Dans l'accès à l'éducation, avec des systèmes automatisés de notation ou d'admission,
- Et également dans l'accès aux soins médicaux, aux crédits bancaires, à la mobilité, et ainsi de suite.
Aux origines du biais algorithmique
Maintenant qu'on en sait plus sur ces biais on peut se demander : d'où viennent-ils ?
Le biais ne trouve pas son origine dans l'algorithme en lui-même, ni dans une volonté maléfique de ses créateurs, mais plutôt dans les données sur lesquelles on entraîne l'algorithme. Les machines sont, à la base, agnostiques, elles ne savent rien, et n'ont pas réellement d'a priori. Puis, elles s'inspirent du réel. Ce sont des apprenants, d'où le terme "machine learning".

Ce que ça signifie, c'est que ces biais ne sont pas inventés par les algorithmes, ils sont initialement présents dans les données d'entraînement. Données bien souvent étiquetées par des humains, ou tout simplement héritées de notre passé. Lorsque les données sont inégalitaires, incomplètes, tâchées par des discriminations historiques, les algorithmes internalisent nos erreurs et reproduisent nos préjugés, quand bien même ils sont basés sur des théories et des modèles mathématiques solides.
Quelles sont les solutions ?
Alors, peut-on faire mieux ? Peut-on corriger ces biais ? Je vous propose quelques pistes.
- 1. Tout d'abord, améliorer les données. On vient de voir que les biais trouvent leur origine dans les données avec lesquelles on nourrit l'intelligence artificielle. Il faut donc, à la source, améliorer la qualité des données, corriger les déséquilibres, et ajouter les exemples manquants.
- 2. Ensuite, une autre piste, c'est de repenser les métriques de performance. C'est-à-dire, plutôt que de simplement regarder une performance générale, moyennée sur toutes les données, on va chercher à évaluer si l'algorithme est biaisé ou non. Le principe est très simple : on calcule les performances selon des sous-groupes de données de test, et on s'assure que ces performances sont égales à travers ces sous-groupes. Si c'est le cas, on valide l'algorithme. Et si on se rend compte qu'il n'est pas égalitaire, on refuse son utilisation.
- 3. Un dernier point : réclamer la transparence. Si ce n'est pas au programme d'arrêter d'utiliser l'intelligence artificielle à l'avenir, on peut au moins exiger que le fonctionnement des logiciels soit disponible à la consultation. Une législation pourrait prévoir que tout logiciel ayant une influence directe sur des décisions de justice, médicales, ou encore de recrutement, soit transparent et consultable. Et pourquoi pas, demander également plus d'explicabilité, c'est-à-dire l'utilisation de modèles d'IA dont on est capable d'interpréter les décisions.
Discussion et conclusion
Bon, il est temps de conclure. On entend parfois l'idée selon laquelle les algorithmes d'IA ne sont pas biaisés car ce sont des machines, froides et rationnelles. S'il y a une chose à retenir de mon intervention, c'est que cette idée est absolument fausse. Les machines, tout comme nous, sont influencées par les données et les idées auxquelles on les expose. Car ce qui amène les algorithmes à être biaisés c'est finalement le même processus qui nous amène nous, en tant qu'humains, à être biaisés : le processus d'apprentissage. Ils apprennent comme nous : en observant. En généralisant. En répétant.
Le biais algorithmique n'est pas une anomalie logicielle. C'est un miroir qui reflète nos propres biais.
Et ce que tout ça montre, c'est qu'au-delà des performances et de l'utilité potentielle d'un programme d'intelligence artificielle, il faut d'abord se demander s'il respecte nos droits fondamentaux : typiquement le droit à l'égalité, le droit à ne pas être discriminé en raison de son genre ou de son origine, le droit à un traitement équitable, le droit à la transparence des décisions qui nous affectent, et même peut-être, le droit à être jugé par un regard humain — conscient de ses limites, mais aussi capable d'éthique.
Avant le déploiement en masse d'une intelligence artificielle, on se devrait de l'interroger, de la disséquer, de la tester à fond, afin d'établir que ces droits fondamentaux sont respectés. Malheureusement cette prudence semble inexistante dans notre société, et, à l'instar du logiciel COMPAS, des algorithmes en tout genre, produits par des sociétés privées, pullulent et sont bien souvent acceptés sans remise en question. Acceptés par la loi, et acceptés par la population.
Pourtant un algorithme qui discrimine, même silencieusement, n'est pas seulement un bug à corriger. C'est une société qui délègue l'injustice — et s'en lave les mains.
Références
Enquête Propublica sur COMPAS :
https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
L'affaire Eric Loomis :
https://hal.science/hal-02566382v1/file/Article_Loomis_Khaled_Dika.pdf
Évaluation des biais :
https://adrienpavao.com/blog/exotic-metrics/exotic-metrics.html